数据来源于kaggle,该数据覆盖了某网购平台4年(2015-1-2至2018-12-30)的部分零售数据,对该数据集建立RFM模型,对客户进行细化分类,因为时间比较久远,设置了2019年1月1日作为日期对照值。R(Rencency):最近一次消费,F(Frequency):消费频率,M(Monetary):消费金额。
导入相关库,设置绘图的中文字体
1 | import datetime |
加载数据集
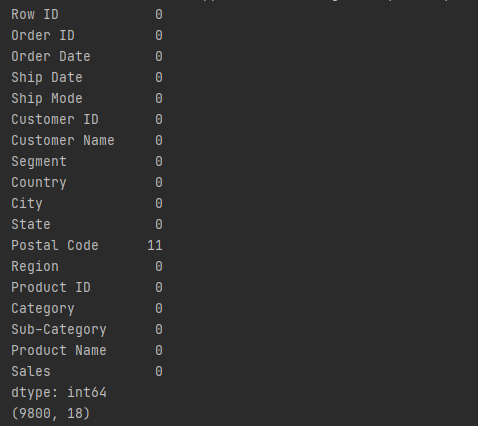
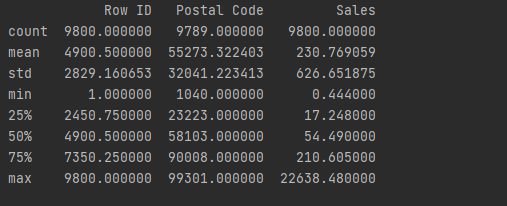
首先看到数据集的大小一共有9800行,18列,大致包括:订单号,订单日期,客户编号,客户名称,国家,城市,产品类别,产品名称,销售金额等。数据集的邮编列有11个空值,本文不会用到邮编列,暂不做处理。单个订单销售额的平均值是230.77,中位数是54.49,最小金额是0.44,最大金额是22638.48,考虑是销售的产品类别跨度较大。
1 | df=pd.read_csv(r'E:\kaggle data\train.csv') |
1 | print(df.describe()) |
数据类型处理
为了便于分析最近一次消费距离2019-01-01的天数,新增了days列
1 | df['Order Date']=pd.to_datetime(df['Order Date']) |
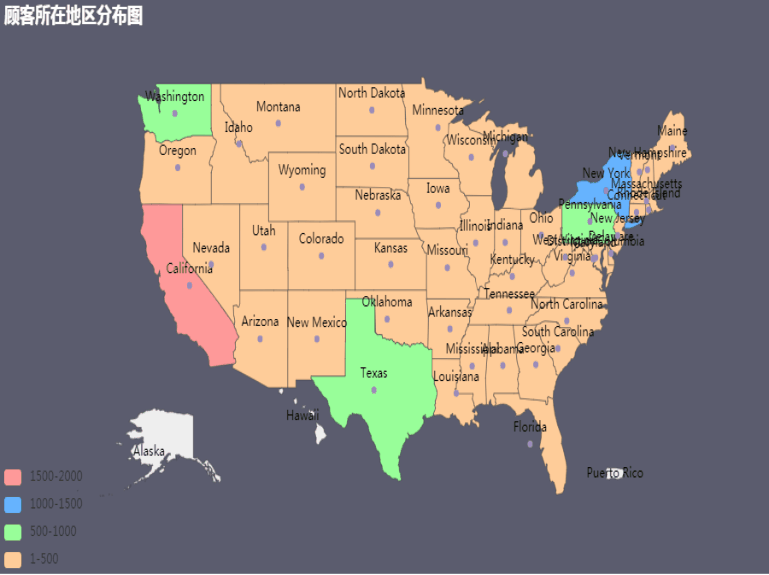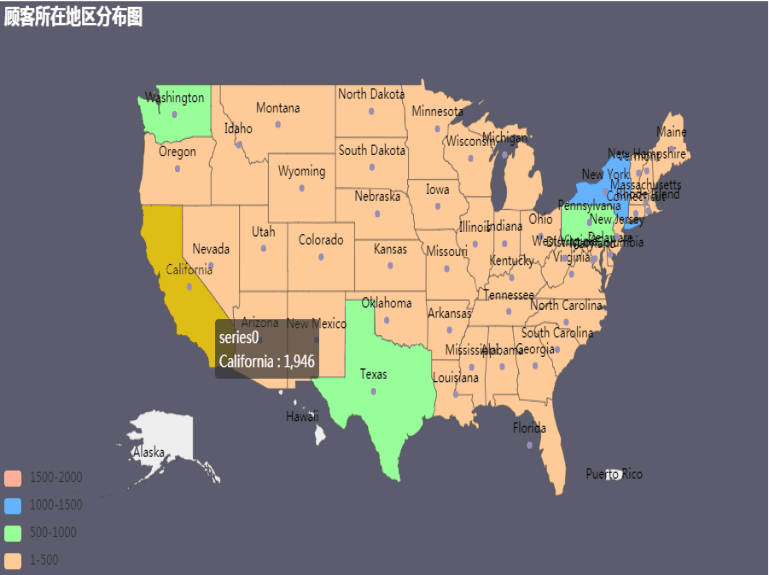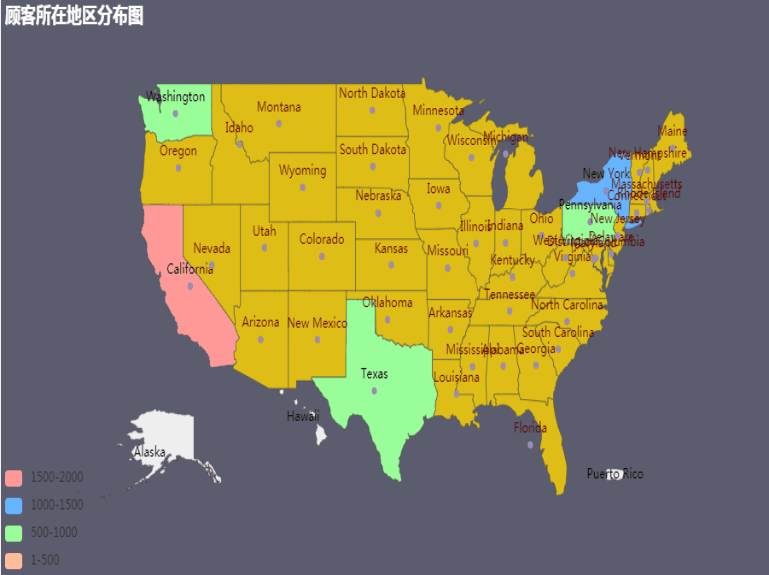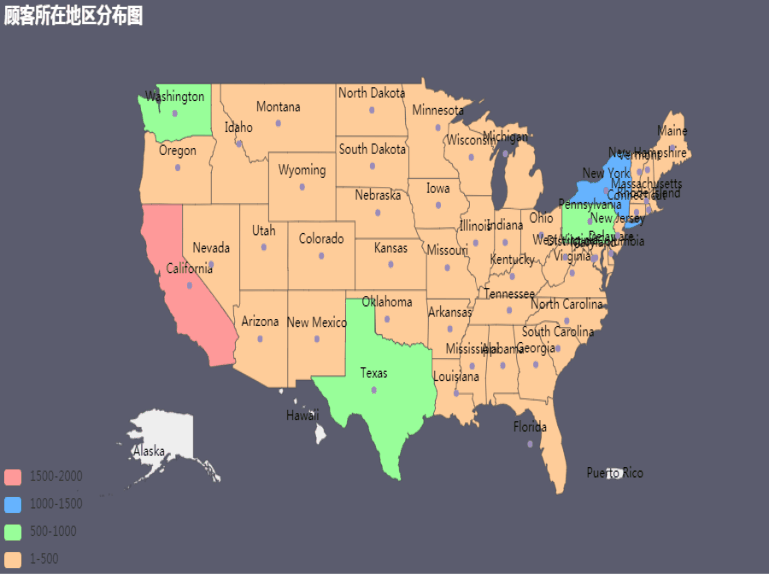
消费顾客的地区分布(2015-2019)
1 | df1=df.groupby('State').agg({'State':'count'}) |
顾客复购周期
每位顾客复购距离上次购买时间之差。
1 | dcc=df[['Customer Name','Order Date']] |
1 | dcc=dcc[dcc['Customer Name'].isin(dcc1['Customer Name'].to_list())] |
1 | dcc3=dcc2.groupby('Customer Name').\ |
1 | print(dcc3['平均复购时间'].sum()/len(dcc3)) |
构造RFM透视表
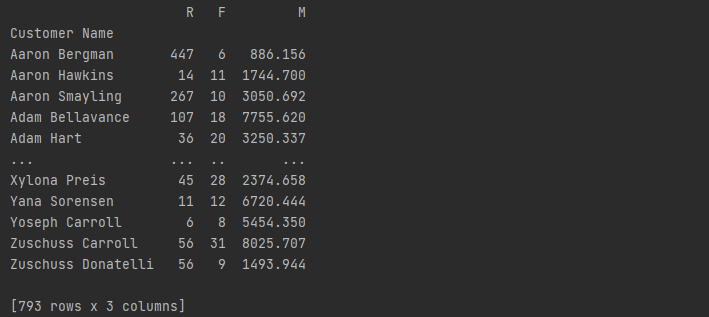
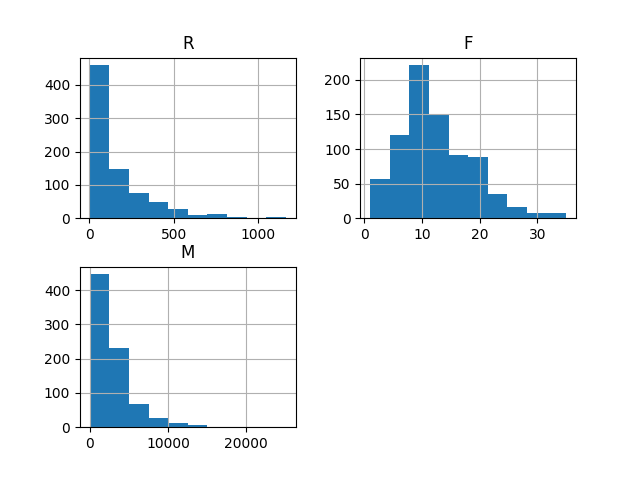
计算出RFM指标,提取对应的列,生成透视表,查看子数据集的数据分布情况
1 | dc=pd.pivot_table(df,index='Customer Name',values=['Sales','days','Customer ID'], |
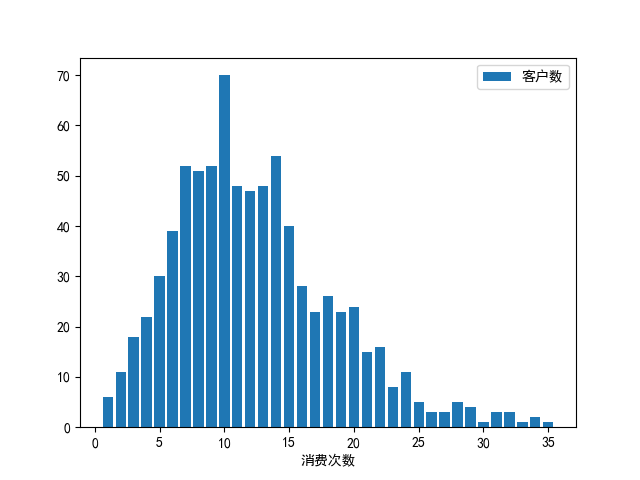
查看客户消费频次的分布情况,这里RFM建模的指标构造按照四分位来分组;例如消费频次前20%的客户群体计5分,后20%的客户群体计1分,本文中,消费次数16次以上计5分,13-16次计4分,10-13次计3分,7-10次计2分,小于7次计1分。
1 | dc1=dc.groupby(['F']).count().sort_values('R',ascending=False) |
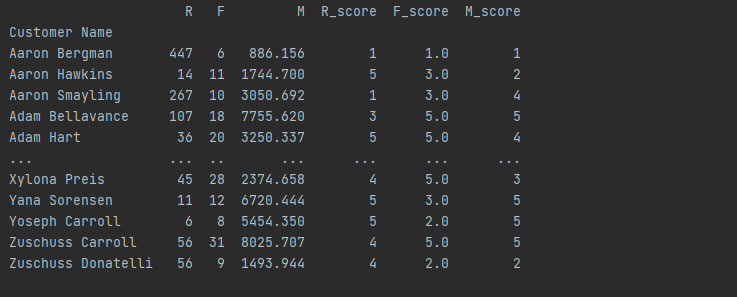
构造RFM梯度策略
*根据子数据集的数据分布情况,把RFM分成5个级别,再将打分的级别求平均值,对应级别大于平均值的,编码为1,小于平均值的,编码为0。
1 | def f1(x): |
1 | a=dc['R_score'].mean() |
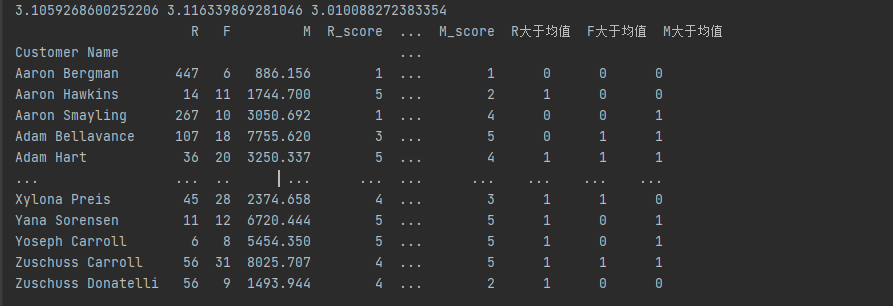
RFM均值计算出来分别是:3.1059268600252206 3.116339869281046 3.010088272383354。接下来给客户贴标签,按照下表中的RFM值设定标签。
| 客户分类 | 用户行为 | 建议 | RFM |
|---|---|---|---|
| 重要价值客户 | 最近消费了,消费频次高,累积消费金额高 | VIP个性化服务 | 111 |
| 潜力客户 | 最近消费了,消费频次高,累积消费金额低 | 多宣传促销商品,附加些价值更高的产品 | 110 |
| 重要深耕客户 | 最近消费了,消费频次低,累积消费金额高 | 积分制,传递会员活动和权益信息,增值客户黏性 | 101 |
| 新客户 | 最近消费了,消费频次低,累积消费金额低 | 邮件或短信推送最近优惠活动,提供免费试用,提升品牌知名度 | 100 |
| 重要唤回客户 | 超出80天无消费,消费频次高,累积消费金额高 | 超大型活动时,电话回访告知客户近期优惠力度 | 011 |
| 一般客户 | 超出80天无消费,消费频次高,累积消费金额低 | 宣传促销活动 | 010 |
| 重要挽回客户 | 超出80天无消费,消费频次低,累积消费金额高 | 宣传形象商品,重大节日活动时,主动联系告知 | 001 |
| 流失客户 | 超出80天无消费,消费频次低,累积消费金额低 | 传递促销信息,恢复客户兴趣,否则暂时放弃 | 000 |
1 | def fun(x): |
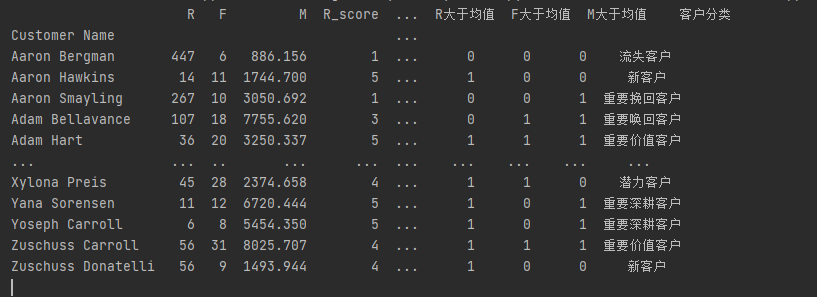
客户分类可视化
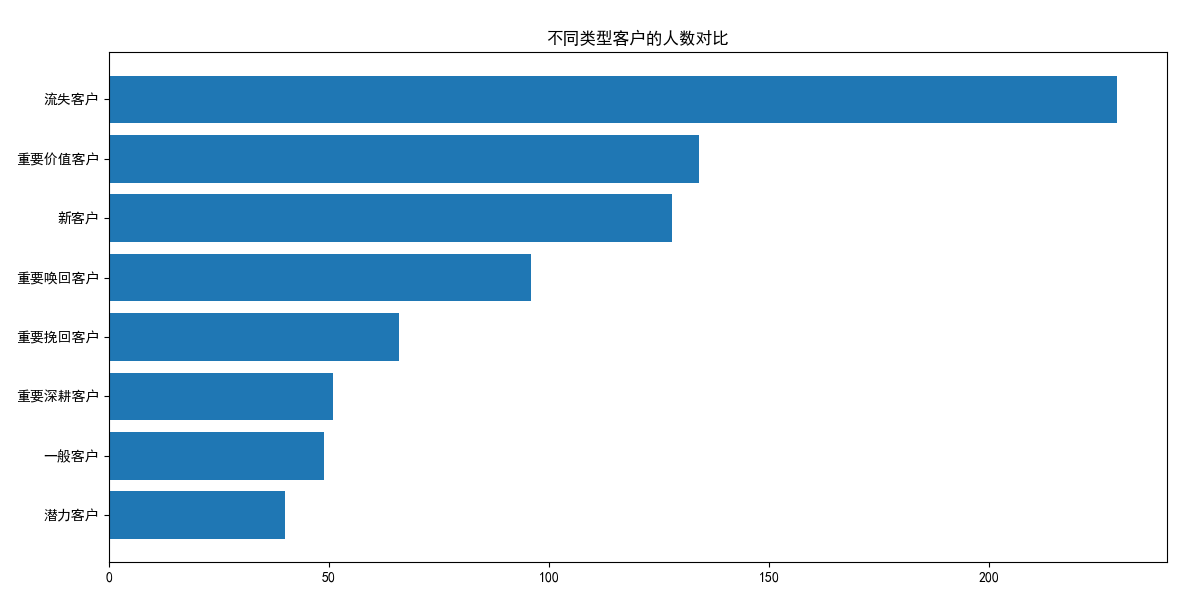
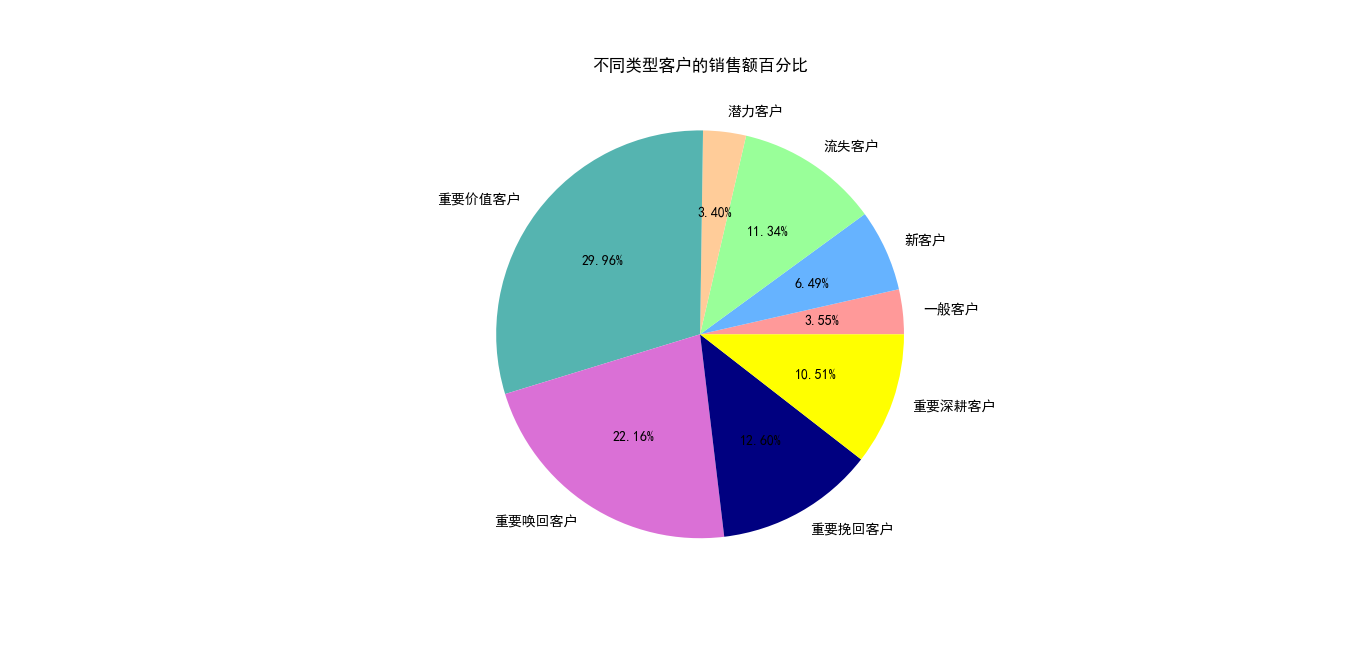
客户分类的人数对比及销售额占比
1 | dc1=dc.groupby('客户分类').count() |
1 | dc2=dc.groupby('客户分类').agg({'M':'sum'}) |
销售金额分段,客户数及销售额占比
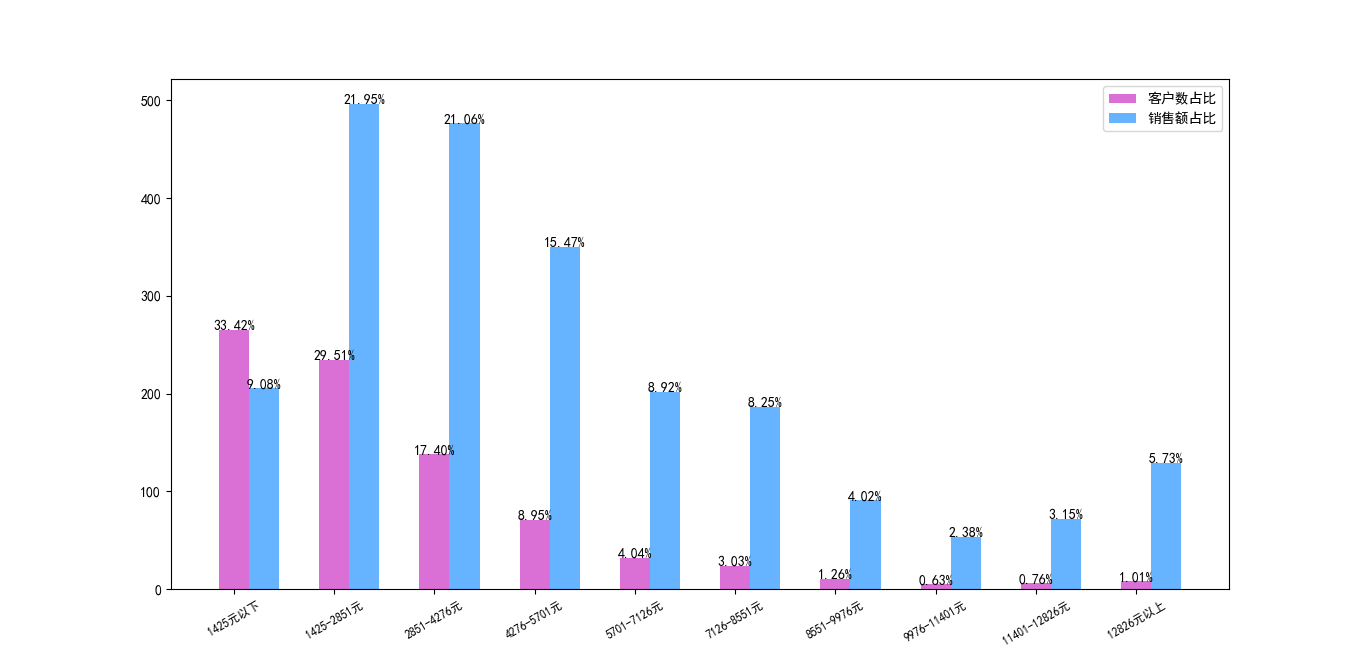
为了验证著名的‘’二八定律“,这里用单个客户的累积购买金额来体现客户消费的差异,总消费金额平均数是2851元,将平均数的1/2作为累积消费金额的分段,则按照1425进行消费金额分段,作出十个分段,可见大多数客户的累积消费金额在4276元(1.5*平均金额)以下,占比80.33%(超4/5),贡献的店铺收入比例占比52.09,剩下的19.67%的客户贡献了将近一半的销售收入。
1 | print(dc['M'].mean()) |
重要深耕客户分析
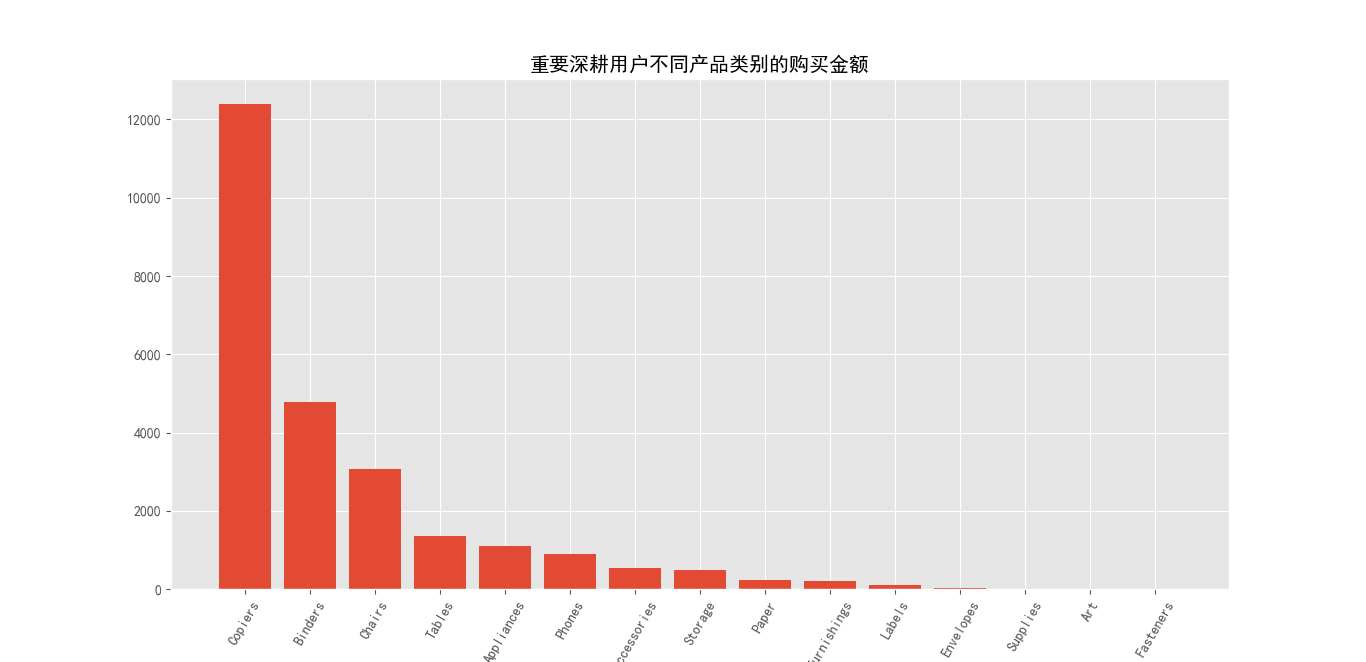
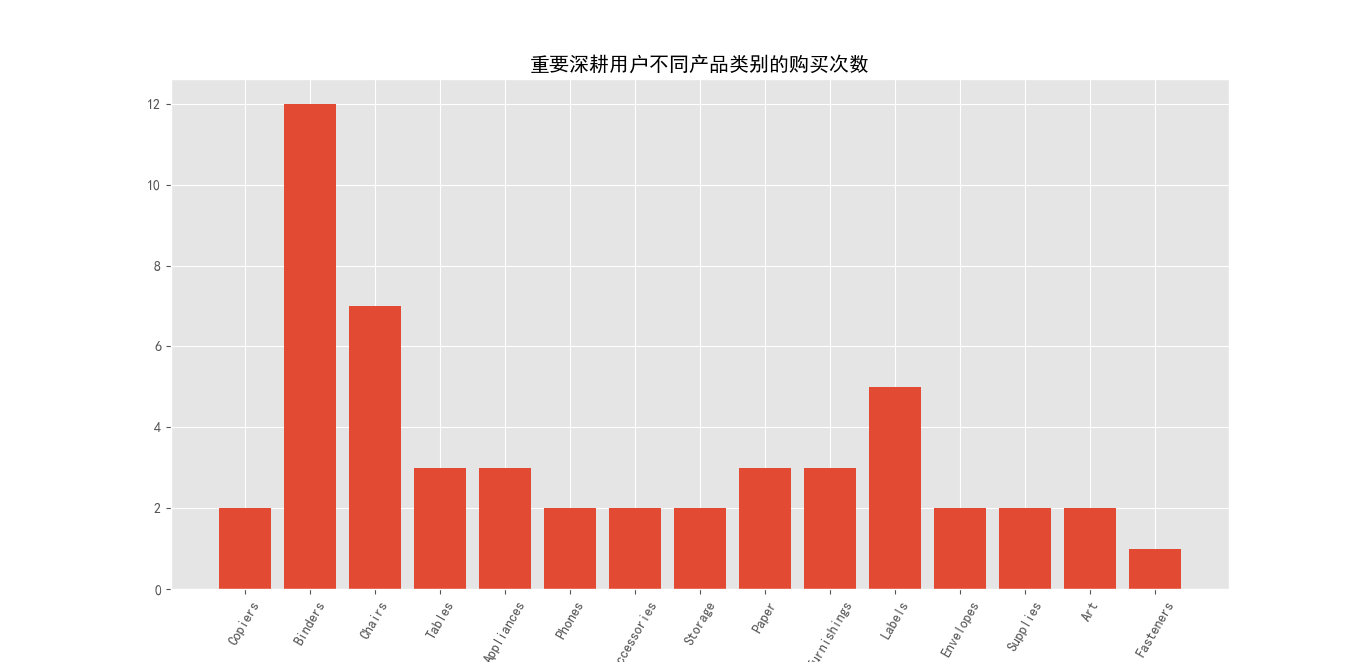
将RFM透视表与主表联结,选取需要的列,重要深耕用户购买前三的产品类别是粘合剂,椅子,标签;销售金额前五的产品类别是复印机,粘合剂,椅子,桌子,器械;复印机,椅子,桌子等单价高,又不属于易耗品,所以该客户群体消费频次低,但是消费金额却相对较高。
1 | dt=dc[dc['客户分类']=='重要深耕客户'] |
1 | dt1=dt.groupby(['Sub-Category']).agg({'Sales':'sum','City':'count'}) |